


Cohen's Kappa 衡量两个相关的分类变量之间的一致性。
容易想到衡量两个变量一致性的方法就是一致的比例,即两个变量一致的观测数除以总的观测数,但是这种方法没有考虑随机的情况下期望的一致性,也就是随机情况预期看到两个变量一致的比例;Cohen's Kappa 就是考虑这种随机期望的方法。计算公式为:
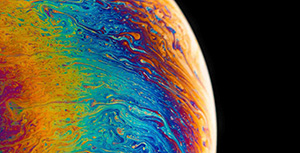
\kappa =\frac{P_0-P_e}{1-P_e}
其中 P_0 是观测到的一致性,P_e 是随机期望的一致性,\kappa 在 -1 ~ 1 之间:
- \kappa = 0 和随机情况一样
- 小于 0,比随机情况差
- 大于 0 ,比随机情况好
以两个医生评估 70 个患者是否为抑郁为例:
## Doctor2
## Doctor1 Yes No Total
## Yes a b R1
## No c d R2
## Total C1 C2 N
##实际例子
## doctor2
## doctor1 yes no Sum
## yes 25 10 35
## no 15 20 35
## Sum 40 30 70
首先计算 P_0,也就是观测到的一致性比例,即对角线上的数字占总的比例:
P_0=\frac{a+d}{N}=\frac{25+20}{70}=0.643
然后计算 P_e,也就是随机情况下预期的一致性比例,分为两步:
-
计算两个医生随机评估病人为抑郁时,两个医生评估 YES 结果能够匹配的概率:
\frac{R_1}{N} * \frac{C_1}{N}=0.5 * 0.57=0.285 -
计算两个医生随机评估病人为抑郁时,两个医生评估 NO 结果能够匹配的概率:
\frac{R_2}{N} * \frac{C_2}{N}=0.5 * 0.428=0.214
最后的结果是两者相加:
P_e = 0.285+0.214=0.499
因此 Kappa 值为:
\kappa =\frac{P_0-P_e}{1-P_e} = \frac{0.643-0.499}{1-0.499}=0.28
拓展到两个多分类变量上:
## rater2
## rater1 Level.1 Level.2 Level... Level.k Total
## Level.1 n11 n12 ... n1k n1+
## Level.2 n21 n22 ... n2k n2+
## Level... ... ... ... ... ...
## Level.k nk1 nk2 ... nkk nk+
## Total n+1 n+2 ... n+k N
定义 Pi+ = ni+/N 为 i 行的和占 N 的比例,以及 P+i = n+i/N 为 i 列的和占 N 的比例:
P_0=\sum_{i=1}^kP_{ii}
P_e=\sum_{i=1}^kP_{i+}P_{+i}
常用的判断参考:
| Value of k | Strength of agreement |
|---|---|
| < 0 | Poor |
| 0.01 - 0.20 | Slight |
| 0.21-0.40 | Fair |
| 0.41-0.60 | Moderate |
| 0.61-0.80 | Substantial |
| 0.81 - 1.00 | Almost perfect |
vcd 包中的 Kappa 函数可以用来计算:
# Demo data
diagnoses <- as.table(rbind(
c(7, 1, 2, 3, 0), c(0, 8, 1, 1, 0),
c(0, 0, 2, 0, 0), c(0, 0, 0, 1, 0),
c(0, 0, 0, 0, 4)
))
categories <- c("Depression", "Personality Disorder",
"Schizophrenia", "Neurosis", "Other")
dimnames(diagnoses) <- list(Doctor1 = categories, Doctor2 = categories)
diagnoses
Doctor2
Doctor1 Depression Personality Disorder Schizophrenia Neurosis Other
Depression 7 1 2 3 0
Personality Disorder 0 8 1 1 0
Schizophrenia 0 0 2 0 0
Neurosis 0 0 0 1 0
Other 0 0 0 0 4
library("vcd")
# Compute kapa
res.k <- Kappa(diagnoses)
res.k
value ASE z Pr(>|z|)
Unweighted 0.6512 0.09968 6.532 6.474e-11
Weighted 0.6331 0.11939 5.303 1.140e-07
# Confidence intervals
confint(res.k)
Kappa lwr upr
Unweighted 0.4557884 0.8465372
Weighted 0.3991025 0.8670846
评论区